2021. 1. 24. 20:19ㆍProject
오늘은 Kaggle사이트에서 가장 유명하고, 기본적인 competition인 타이타닉 생존자 예측을 해보려고 합니다.
이번 분석은 JupyterNotebook을 사용하였으며, 제가 작성한 code는 github사이트에 올려놓았습니다.
먼저, kaggle 사이트에 들어가서 아래와 같은 competition을 찾습니다.

저는 위 competition을 참여할 것이며, Data들 또한 위에서 내려받았습니다.
이번에는 jupyternotebook을 사용하여 분석을 실시할 예정인데, 이것의 장점은, vscode와 다르게 텍스트를 작성하여 소제목, 큰 제목등을 설정할 수 있으며, vscode와 다르게 code를 하나하나씩 분석한 결과를 얻어낼 수 있습니다.

먼저 내려받은 파일을 내 jupyter_notebook에 저장후 파일을 한번 살펴보았습니다.
각 카테고리에 대한 설명을 해보자면 아래와 같습니다.

그리고 데이터에 대한 정보를 한번 살펴보겠습니다.

train data를 확인해보면 탑승객은 총 891명인데 Age, Cabin, Embarked는 탑승객의 정보와 맞지 않는다는 것을 확인할 수 있다. 이는 유실된 정보이며, 데이터 정제 과정에서 데이터를 손 볼 필요가 있다.
유실된 정보에 의미있는 정보를 넣어주는 작업이 필요한데 이 과정을 fiture Engeenering라고 한다.
누락된 정보를 확인해 보면 아래와 같습니다.

이번에는, 현재 있는 데이터를 시각화하여 유의미한 부분을 찾아보려 합니다.
먼저, 아래 코드를 작성하여 데이터 시각화를 하기위한 코드 준비를 실시합니다.

성별에 따른 생존자를 파악해 보겠습니다.

위, 차트를 보면 여성이 남성보다 더 많이 생존하였다는 가설을 확인할 수 있으며,
"Sex"데이터가 유의미한 데이터라는 것을 확인할 수 있습니다.

이번에는 Pclass(등급)의 유의미성을 확인해 보았는데,
1등급의 승객일 수록 3등급의 승객보다 더 많이 생존할 가능성이 높다는 가설을 설정할 수 있습니다.
이번에는 Sibsp와 Parch의 유의미성을 확인해 보겠습니다.

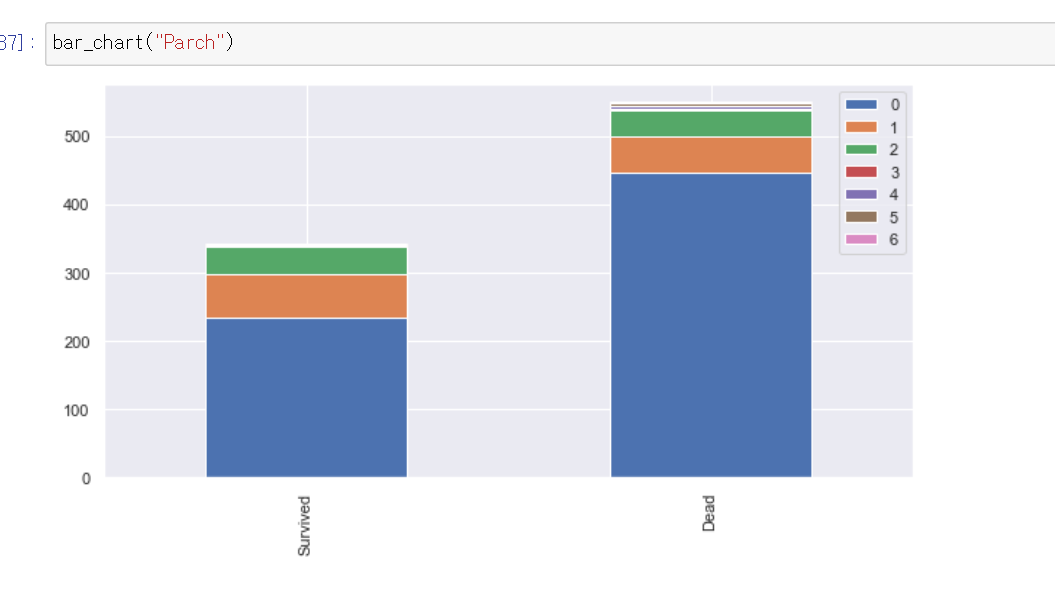
두개의 항목 둘다, 가족, 친인척의 내용입니다.
차트를 보면 둘다 유사한 내용의 정보를 담고 있는것을 확인할 수 있습니다.
즉 혼자 탑승했을경우 사망할 확률이 높아지고, 가족과 함께 탈 경우 생존할 확률 이 더 높아집니다.
마지막은 선착장에 대한 유의미성을 파악해 보겠습니다.

Q-R-S의 순서대로 생존자가 제일많으며, 사망자도 제일 많습니다.
딱히 유의미한 가설을 세우기 힘들다고 판단됩니다.
이번에는 Feature engineering을 통해 무의미한 칼럼들의 정보를 유의미하게 바꾸어 주고, 필요한 데이터와 필요없는 데이터를 가공하여 데이터 정제를 해보려 합니다.
먼저 name 컬럼을 살펴보겠습니다.

저는 이름 Mr,Miss,Mrs을 제외한 것들을 하나로 합치려 합니다.

위와 같은 코드를 작성해 주었고, 이를 다시 확인해보면, Title의 칼럼이 0, 1, 2, 3 으로 변경된 것을 확인해볼 수 있습니다.
이를 차트로 확인해보면, 아래와 같이 확인되는 것을 알 수 있습니다.

이제 Title(성)에 대한 데이터 가공이 끝났고,
저는 Name(이름)에 대한 데이터가 유의미하지 않다고 판단하였습니다.
따라서, Name 칼럼을 제거하도록 실시하였습니다.

위와 같이 코드를 작성하여 Name칼럼을 제거하였고, 데이터를 확인해보면 Name 컬럼이 제거된것을 확인할 수 있습니다.
그, 다음 모든 데이터들의 수치화를 위해 성별데이터를 가공해보려 합니다.
현재 Sex칼럼의 데이터들은 male/ female로 설정되어있습니다.
male은 0, female은 1로 데이터를 가공해보려 합니다.
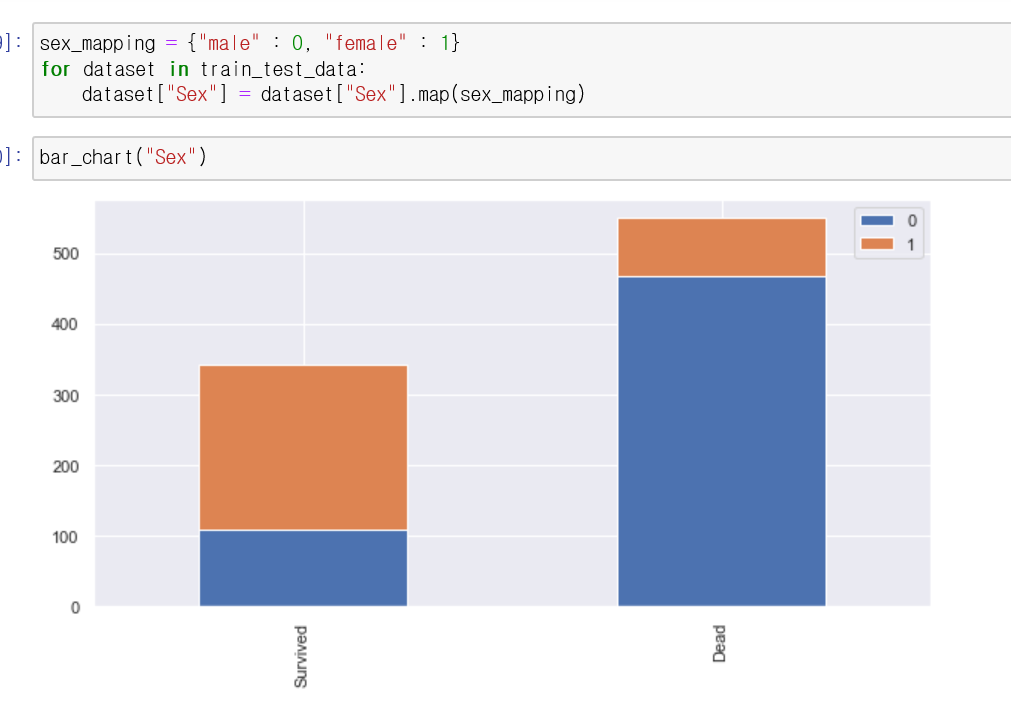
위와 같은 코드를 작성하였고, 차트를 확인해보면 앞서 보았듯이 여성이 남성보다 더 생존할 가능성이 높다는 가설을 확인할 수 있습니다.
이번에는 Age칼럼을 확인해 보겠습니다.

상위 100개의 데이터를 확인해 본 결과 Age 칼럼에 데이터가 NaN이라고 나오는 부분이 있습니다.
이부분은 데이터가 유실된 부분이며 이를 유의미한 정보로 가공해줄 필요가 있습니다.
유의미한 정보를 가공해주는 방법은 분석자에 따라 다양한 방법이 있습니다.
저는 앞서 설정한 Title에 대한 정보를 사용하여, 유실된 Age를 해당 데이터의 Title의 중앙값으로 설정해 보겠습니다.

위와 같이 코드를 작성하였고, 확인해 본 결과 데이터 가공을 하기전에 NaN이였던 정보들이 새로 가공되었다는 것을 확인할 수 있습니다.
이번에는, 설정한 Age를 통해 전체 연령에 대한 생존자를 확인해 보겠습니다.

위 그래프를 보면, 20-40대가 사망할 확률이 매우 높은것을 확인할 수 있습니다.
즉 Age의 칼럼이 유의미한 정보를 담고 있다는 것을 확인할 수 있습니다.
저는 Age에 대해 구간화를 통해 범주화 시키려 합니다.
이러한 과정을 Binning이라고 하며, 아래와 같이 구간화를 실시해 보려 합니다.

이러한 구간화를 코드를 작성하고 확인해보면,

Age칼럼의 데이터의 구간화가 잘 시행된 것을 확인할 수 있습니다.
차트를 통해 확인해보면,

2.0(26~36)의 승객들이 가장 많이 사망했다는 정보를 확인할 수 있습니다.
이번에는 선착장에 대한 데이터를 가공해 보려 합니다.
앞서, 선착장에 대한 데이터를 확인해본 결과, 어떠한 유의미한 정보도 확인할 수 있었습니다.
이번에는, 등급 좌석에 따른 선착장을 확인해 보려 합니다.
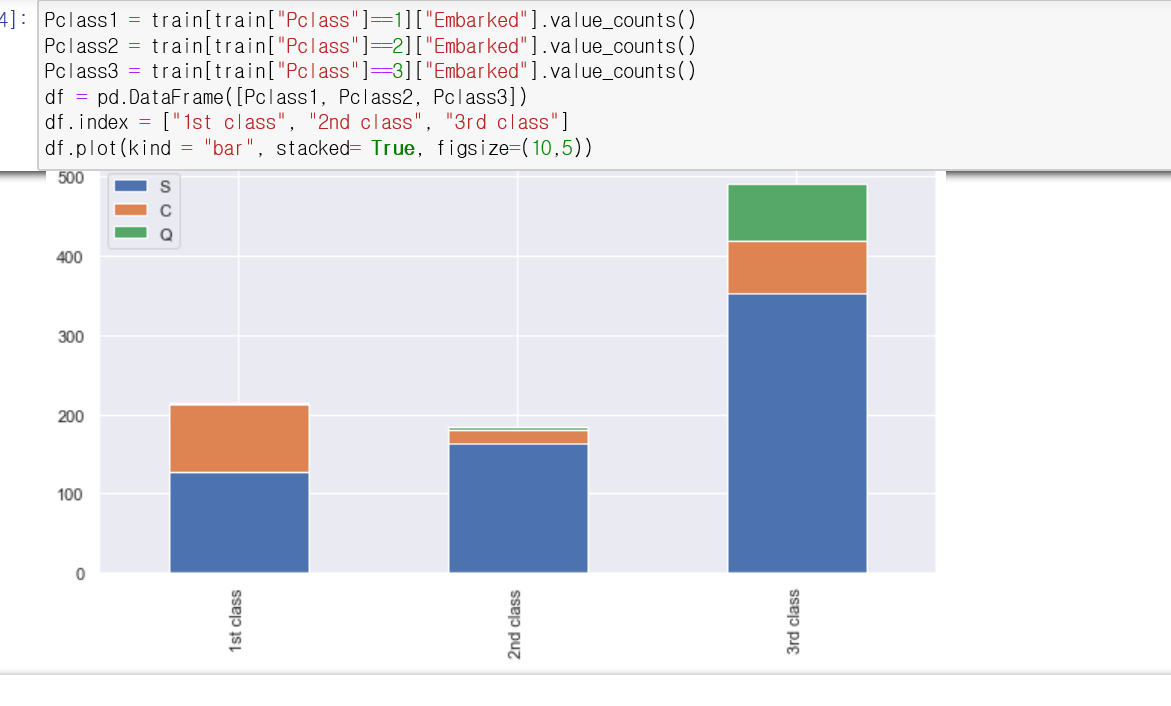
각 1등급, 2등급, 3등급에 따른 선착장의 정보를 차트를 통해 확인해 보았습니다.
여기서 알수 있는 정보는 대부분 S선착장에서 탑승한 정보를 확인할 수 있으며,
1, 2등급 칸에 승객들은 Q선착장에서 탑승한 사람들이 거의 없다는 정보를 확인할 수 있습니다.
여기서 저는 'Q선착장이 3등급 칸에만 탑승한 사실을 보아 Q선착장이 상대적으로 저소득인 사람들이 탑승했다는 사실을 유추해 보았습니다.'
그리고 대부분 S선착장에서 탑승한 사실을 기반으로 Embarked에서 가지고 있는 NaN값들을 모두 S로 변경해야 겠다고 필자는 판단하였습니다.

위와 같이 유실된 데이터를 전부 S로 바꾼후, 수치화를 위해 각 선착장들을 모두 숫자로 변경한 이후 데이터를 확인해 본 결과, 새로운 데이터가 적절하게 가공된 것을 확인할 수 있습니다.
이번에는 Fare(요금)컬럼에 대한 데이터 가공을 실시해 보겠습니다.
먼저, Fare컬럼에서 유실된 데이터를 각 좌석 등급의 중앙값으로 NaN값을 설정하겠습니다.

위와 같이 작성하여 그래프를 통해 분석해보면,
요금이 낮을수록 더 많이 사망했다는 정보를 알 수 있습니다.
여기서 저는 '저소득자일 수록 더 많이 사망했다.'라는 정보를 유추해 볼 수 있었습니다.
그리고 이 티켓 요금에 대한 정보를 구간화 하였습니다.

각 티켓 요금에 따른 구간화를 실시하였고 train데이터를 확인해본 결과 데이터 가공이 잘 실시되었다는 사실을 확인할 수 있습니다.
이번에는 Cabin에 대한 데이터를 가공해 보겠습니다.
먼저 Cabin에 대한 데이터를 살펴보면,

아래와 같이 알파벳+숫자 구성되어 있는 것을 확인할 수 있습니다.
Cabin의 데이터를 좌석의 등급과 연관하여 분석해 보겠습니다.

위와 같이 코드를 작성하여, 차트를 확인해보면, 1등급 좌석의 승객들이 대부분의 Cabin을 보유하고 있다는 사실과, 1등급에만 A, B, C, D, E가 존재한다는 정보를 알 수 있습니다.
저는 여기서 "1등급 좌석의 승객들, 즉 고소득의 승객들이 Cabin을 많이 보유할것이다."라는 정보를 유추해 볼 수 있습니다.
그리고 Cabin의 값들을 수치화 하기 위하여 코드를 작성하였고,
Cabin의 NaN값들을 각 Pclass의 Cabin 중앙값으로 대체하여 정보를 가공하였습니다.

그리고 수치화하는 코드에서 소숫점을 사용한 이유는 각 범주의 차이를 크게 두지 않고 범위를 비숫하게 주기 위하여 소숫점을 사용하였습니다. 이러한 과정을 fiture scaling이라고 합니다.
이번에는 FamilySize라는 컬럼을 생성해 보려 합니다.
앞서 Sibap와 Parch컬럼을 분석해 본 결과 둘다 유사한 결과가 나오는다는 정보를 확인하였습니다.
그리고 컬럼의 내용도 의미적으로 같기 때문에 둘의 정보를 합쳐서 FamilySize라는 새로운 컬럼을 만들어 보려 합니다.

위와 같이 코드를 작성하여 두 컬럼을 합쳐 FamilySize라는 컬럼을 작성하였습니다.
새로 만든 컬럼을 분석해보면,

위와 같은 결과가 나오고, 앞서 sibsp와 parch의 결과와 같이,
혼자 탈 경우 높은 확률로 사망할 가능성이 높아지고,
가족이랑 탈 경우 생존할 확률이 높아진다는 정보를 알 수 있습니다.
그리고 FamilySize의 데이터들의 구간화를 좀더 세분하게 하여 데이터를 가공해보겠습니다.
이를 하는 이유는 예를 들어 , 혼자탄경우 와 4명과 탄 경우 FamilySize라는 컬럼에 의해 생존가능성의 확률이 너무 차이가 나기 때문에 이를 방지하기 위해 Feature Scaling작업을 실시하겠습니다.

위와 같이 FamilySize의 데이터에 Feature scaling작업을 실시하였고, 데이터를 확인한 결과 작성한대로 데이터들이 잘 가공되었다는 것을 확인할 수 있습니다.
이번에는 데이터에서 필요없는 데이터를 삭제해 보려 합니다.
Ticket 정보는 필요가 없고,
SibSP와 Parch는 FamilySize의 데이터로 합쳤기 때문에 더이상 필요가 없습니다.

위와 같이 코드를 작성하고 데이터를 확인해보면, 불필요한 컬럼들이 삭제된것을 확인할 수 있고,
데이터들이 전부 수치화되고 NaN데이터들또한 원하는 대로 변경되어 데이터를 분석하기 위해 필요한 데이터로 잘 가공된 것을 확인할 수 있다.
이번에는 target데이터를 생성해보려 한다.

먼저 train데이터에서 "Survived"컬럼을 제거하여 train_data데이터를 생성하고
train데이터에서 "Survive"컬럼만을 추출하여 target데이터를 생성한다.
이는 train_data를 분석하여 target의 생존자 여부를 파악하기 위한 작업이라고 생각하면 된다.
그리고 이번에는 모델링 작업을 실시해보려 한다.
모델링기법에는 다양한 방법이 있습니다.
저는 분류모델을 통해 여러 점수를 메겨본 후 가장 최적의 모델을 찾아 예측을 해보려 합니다.

먼저 사용할 모델링 기법의 라이브러리를 불러오고 ,
가공한 train데이터의 정보를 확인해본 결과 처음 정보를 확인할때와 다르게 승객별로 모든 데이터들이 유실된 정보 없이 891개가 정확히 들어와 있는 것을 확인해 볼 수 있습니다.

먼저 K-fold를통해 교차 분석을 해보겠습니다.
이는 10개로 나누어서 순서대로 10번을 분석하는 방법입니다. 데이터를 섞는 과정은 랜덤이며, 이를 기분으로 뒤에 분류분석을 실시할 예정입니다.

K-NN은 근접이웃방법으로 근처에 있는 모집단을 묶는 방법입니다. 이를 "accuracy"(정확도)와 K-fold기반으로 10번을 분석하며 얼마나 target데이터와 유사한지 이에 대한 점수의 평균을 내어서 82.6임을 확인할 수 있습니다.

이번에는 의사결정 나무로, 앞선 데이터 모델링 방법과 유사하게,
train_data를 기반으로 target을 분석하여 얼만큼 정확한지 나온 점수와 평균을 확인하였습니다.


앞서 나이브 베이지안 방법과 SVM분류방법을 실시해 보았습니다.
평균 점수 중에 SVM분류방법의 점수가 가장 높은것을 확인해보았습니다.
그래서 저는 SVM의 기법을 선택하였습니다.
이때까지는, train_data를 기반으로 target을 분석하는 방법이였으면,
이러한 모델링으로 최종 데이터인 test데이터를 분석해보겠습니다.

SVC함수를 만들고,
clf.predict()함수로 test_data를 분석하여 predicitoin이라는 파일을 생성하였습니다.
모든 분석이 끝났습니다.
이를 Kaggle에서 원하는 데이터 형식 파일로 변환하겠습니다.

모든 작업이 완료되었고,
제출할 파일인 submission파일을 확인해보면,

892번 승객부터 1309번까지의 생존여부가 0과1로 예측되는 사실을 확인할 수 있으며 이에 대한 파일이 csv파일로 폴더에 생성된 사실을 확인할 수 있습니다.
모든 코드 작성이 완료되었고, 제출할 파일도 생성해 보았습니다.
이제 kaggle competition에 제출해보겠습니다.

확인해본 결과,

2,300,000개의 팀중 130,000등의 순위를 낸것을 확인할 수 있습니다.
점수는 0.77272를 받았으며 , 상위 17프로정도로 나쁘지 않은 성적을 낸 것을 확인할 수 있습니다.
제 첫 Kaggle 프로젝트 였으며, 모든 jupyterNoteboom내용과 Code작성 내용과 데이터, 제출용 데이터는 모두 제 github사이트에 올려놓았습니다.
sungmin808/kaggle
kaggle competition data. Contribute to sungmin808/kaggle development by creating an account on GitHub.
github.com
'Project' 카테고리의 다른 글
| [엔지니어링산업 설계대전] (0) | 2021.06.20 |
|---|---|
| [Dacon]영화 관객수 예측 모델 (0) | 2021.01.28 |
| [Dacon]따릉이 이용 예측 AI모델 (0) | 2021.01.27 |
| [Kaggle]Covid in 한국 (0) | 2021.01.21 |