2021. 1. 28. 18:58ㆍProject
오늘은 데이콘에서 진행하는 영화 관객수 예측 모델을 만들어 보려 합니다.
2010년대 한국에서 개봉한 한국영화 600개에 대한 감독, 이름, 상영등급, 관객수 등의 정보가 담긴 train데이터를 가지고 test데이터에 대한 관객수를 예측하는 프로젝트입니다.
해당 홈페이지의 사이트는 아래 기재해 놓겠습니다. 여기서 train데이터와 test데이터를 받을수 있으며, 본인이 만든 모델을 가지고 결과물을 제출하고 평과받으며 순위를 받을수 있습니다.
https://dacon.io/competitions/open/235536/data/
[문화] 영화 관객수 예측 모델 개발
출처 : DACON - Data Science Competition
dacon.io
저는 JupyterNotebook을 사용하여 코드를 작성하였으며,
제 github주소에 제가 작성한 코드와, 결과물, 그리고 train데이터와 test데이터 또한 올려놓겠습니다.
https://github.com/sungmin808/kaggle/tree/master/movies
sungmin808/kaggle
kaggle competition data. Contribute to sungmin808/kaggle development by creating an account on GitHub.
github.com
이제 제가 작성한 코드를 보며 하나씩 살펴보도록 하겠습니다.

가장 먼저 데이터들을 불러오고 데이터를 살펴보겠습니다.

데이터를 살펴보면 문자열인 데이터들 도 있고, 수치화된 데이터들이 있습니다. 또한 데이터들 중에 NaN값들로 된 결측값들도 있습니다. 머신러닝을 작동시키기 위해서는 수치화된 데이터들이 있어야하며, 결측값들 또한 처리를 해주어야 합니다.
데이터를 살펴본후, 데이터 전처리 과정에서 머신러닝을 작동시키기 위한 작업들이 필요할것이라고 인지하였습니다.

컬럼들을 살펴보겠습니다.

각 컬럼들을 위와 같고 결국 우리가 예측해야할 부분은 바로 "box_off_num"관객수 입니다.
그리고 이 부분에서 데이터를 분석하기전 컬럼들을 잘 이해하고 넘어가야 합니다.

그리고 데이터의 행, 열들을 확인해 보았습니다.
train데이터에 600개의 영화들이 있고 이를 분석하여 만든 모델을 바탕으로, 243개의 영화의 관객수를 예측해야 합니다.

좀더 자세하게 컬럼들을 분석해본 결과, 7번째 컬럼인 dir_prev_pfnum에 결측값이 발생했다는 정보를 파악할 수 있습니다.
7번 컬럼의 의미는, 해당 감독이 이 영화를 만들기 전 제작에 참여한 영화에서의 평균 관객수(단 관객수가 알려지지 않은 영화 제외)입니다.

test데이터를 확인해본 결과 이 데이터에도 해당 컬럼에 결측값이 있다는 정보를 확인하였습니다.
따라서, 이 부분에 결측값을 채워주어야 합니다.

필자는 이 부분을 해당 컬럼이 NaN인 값들인 영화의 감독의 평균 dir_prev_bfnum을 구해서 그 값을 데이터에 집어 넣으려고 했습니다.

따라서 위와 같이 입력해본 결과, 오류가 발생하였습니다.
이는 600개의 영화중 해당 컬럼이 결측값인 데이터의 감독들의 평균값을 구하지 못하였는데, 이는 해당 감독들이 다른 영화는 제작하지 않았다는 의미입니다. 따라서 저는 다른 방법으로 결측값 처리를 해야하였습니다.
필자는 앞서 데이터를 분석할때, 컬럼을 보고 7번 컬럼인 dir_prev_bfnum과 8번 컬럼인 dir_prev_num과 매우 연관된 데이터라고 생각하였습니다.
왜나면, 8번 컬럼은 해당 감독이 이전에 제작했던 영화의 개수를 알려주는 것이고, 7번 컬럼은 이러한 영화들의 평균 관람객수를 알려주는 데이터입니다.
따라서, 8번 컬럼의 데이터가 0이라면 이전에 제작했던 영화가 없다는 의미이며, 당연히 7번 컬럼의 값도 0이 나와야 합니다.

따라서, dir_prev_bfnum이 결측값인 데이터들의 dir_prev_num의 값들을 모두 합한 결과 0이 나왔습니다.
따라서 dir_prev_bfnum의 결측치들은 모두 0이라고 판단할 수 있습니다.
test데이터 또한 마찬가지의 결과가 나왔고,
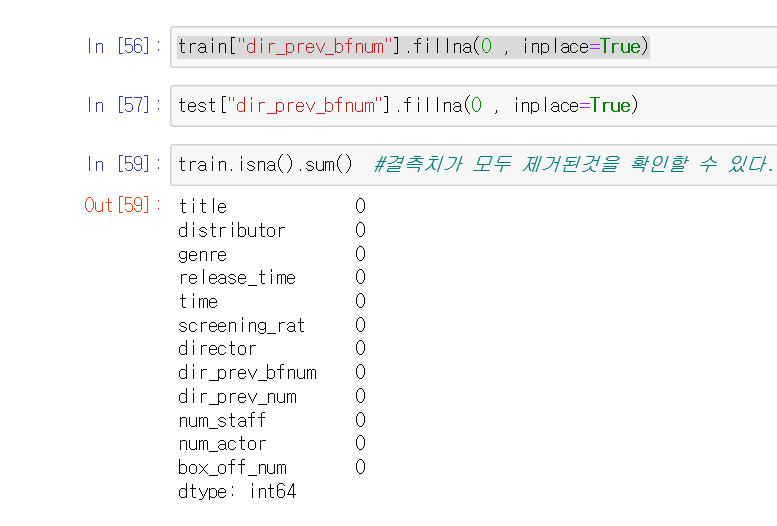
위와 같이 결측치들을 모두 '0'으로 집어넣고 확인하면, 모든 결측값들이 제거된것을 확인할 수 있습니다.

이번에는 변수들을 선택하여 모델을 구축해보려 합니다.
머신러닝에서 변수들은 수치형 변수들을 사용해야 정상적으로 작동할 수 있습니다.

LGBMRegressor모델을 만들어 보려 합니다.
random_state =777로 고정시켜주는 이유는 어느 pc에서나 결과값이 같게 나오도록 고정해주는 코드입니다.
features라는 변수를 만들고 train의 수치형 변수들만 넣어줍니다.
그리고 y_train은 train에서 y값이라 할 수 있는 관객수를 넣어 주었습니다.

그리고. 이번에는 만든 모델을 가지고 학습을 해 볼 것이며,
점차 좋은 모델을 만들어보도록 검증을 해보겠습니다.
모델을 검증할 순서는 위와 같습니다.

그리고, 처음에 만든 모델을 가지고 X_train과 Y_train 데이터를 학습시키고, 학습시킨 모델로 X_test에 적용시켜 제출할 결과값을 만들고 제출용 csv파일을 생성하였습니다.
그리고, 만든 결과값을 살펴보았습니다.
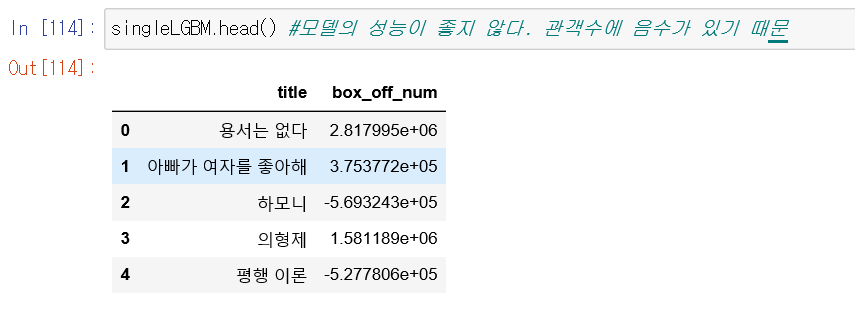
만든 결과물을 보았을때, 모델의 성능이 좋지 않아 좋은 결과를 얻었다고 할수 있습니다.
왜냐하면 box_off_num은 관객수를 의미하는데, 이것이 음수가 될수는 없기 때문입니다.
그래서 이번엔, 만든 모델을 K-Fold교차 검증을 통해 더 좋은 모델로 만들어 보겠습니다.
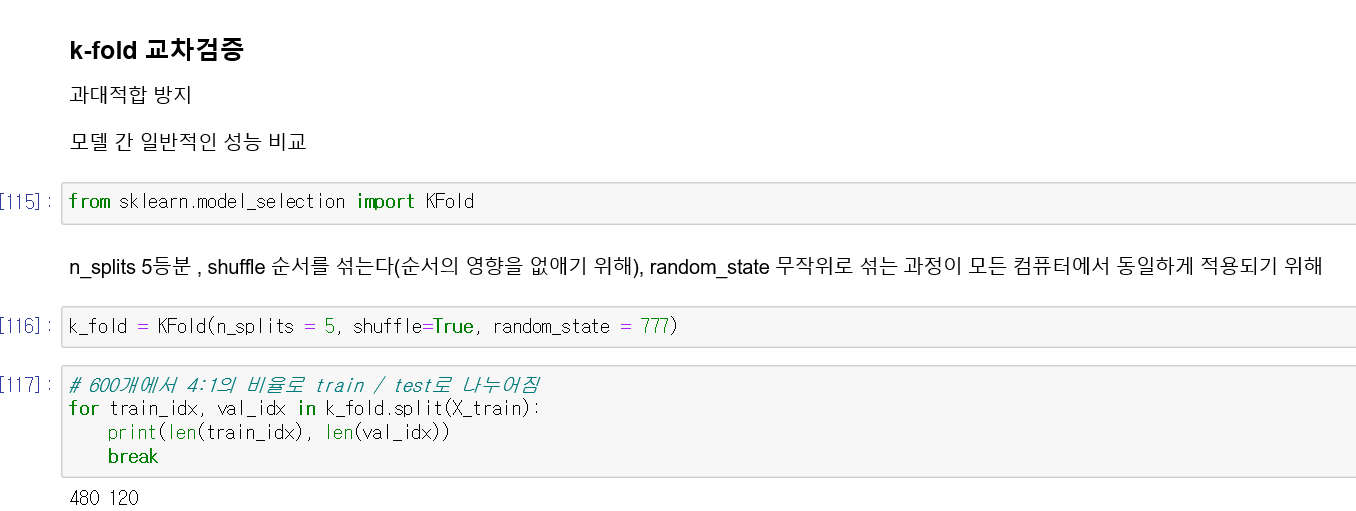
K-fold 교차검증은 과대적합을 방지하며 모델 간 일반적인 성능을 비교합니다.
K-fold를 쉽게 설명해보자면 데이터를 n개로 분할하여 랜덤으로 n번을 돌아가며 분석을 하는 것입니다.
예를 들어 한개의 데이터를 o o o o o와 같이 5개로 분할하였습니다. (o : val_idx , o : train_idx)
그렇다면, o o o o o, 와 같이 val데이터를 번갈아가며 train과 분할하며 분석하는 것입니다.
o o o o o,
o o o o o,
o o o o o,
o o o o o
위의 코드를 살펴보면 n_splits =5 로 하여 5분할 하여 600개의 데이터를 480, 120으로 나누어 분석하는 것을 확인할 수 있습니다.

그리고 만든 데이터를 가지고 모델링을 하였습니다.
eval_set :평가기준
early_stopping_rounds :어느 정도 시점이 되면 학습을 중단시켜주는것, 100번의 과정동안 더이상 유의미한 모델의 성능 증가(오차율)가 되지 않는다면 중지
verbose :100번째 모델마다 출력값 산출
분할한 데이터들을 가지고 최적의 models을 만들었습니다.

이제 만든 모델을 가지고 preds를 만들어 주었습니다.

작성한 preds를 바탕으로 preds의 평균값을 np.mean()으로 하여 결과값을 만들었습니다.
만든 결과값을 확인해본 결과 전의 결과값과 다르게 음수는 없는것으로 보아 좀더 좋은 모델을 생성하였다고 할 수 있습니다.

이번에는 변수에 대해 좀더 확인해 보겠습니다.
현재 변수는 features에 위와 같이 원래 수치화된 컬럼들만을 변수로 지정했었습니다.
그래서 무언가를 더 추가하면 더 좋은 결과를 얻을 수 있지 않을까 고민해 보았습니다.
원 변수를 다시한번 살펴보면,

genre인 장르를 보면 중복되는 장르들도 많고 분류하기도 어렵지 않아 보였습니다.

따라서 preprocessing라이브러리를 불러와 장르의 문자열 값들을 모두 숫자로 변경해 주었습니다.
이를 확인해보면, 위와 같이 각 장르들이 수치화 된것을 확인할 수 있습니다.
test데이터에도 위와 같은 방법으로 genre컬럼을 수치화시켜주었습니다.

그리고 features 에 genre컬럼을 추가시켜준후,
앞선 방법과 같이 모델을 만들고,

결과값을 생성한후 제출파일에 맞추어 생성하였습니다.
(결과값의 정확률은 밑에 Dacon 홈페이지에서 점수를 받은것을 보며 어떤 모델이 가장 성능이 좋은지 확인해보겠습니다.)
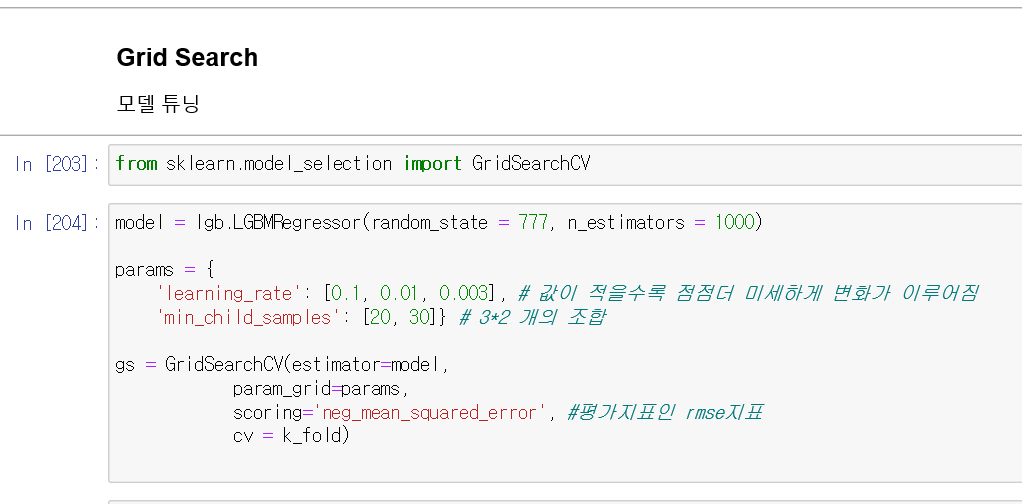
이번에는 작성한 모델을 가지고 모델튜닝을 해보겠습니다.
params에서
learning_rate는 모델링을 하는 간격으로, 값이 적을수록 점점 더 미세하게 결과값이 변화하는것을 확인할 수 있습니다.
작성한 params을 가지고
GridSearchCV()로 튜닝을 진행하였습니다.
scoring을 rmse로 한 이후는 현재 이 대회의 평가지표가 rmse값이기 때문에 이렇게 설정하였습니다.

위와 같이 튜닝을 하고, X_train값과 Y_train값에 fit을 적용하였습니다.
그리고 튜닝의 최적의 파라미터값을 확인해본 결과 learning_Rate : 0.003, min_child_samples : 30 인 것을 확인하였습니다.

앞선 방법으로 모델링을 시작하는데,
이번엔 model을 생성할때 앞서 튜닝하여 확인한 최적의 파라미터값을 지정해주고 모델링을 진행하였습니다.

그리고 앞선 방법과 같이 제출파일로 생성하였습니다.
이제 Dacon의 대회 홈페이지로 들어가 결과물을 제출해보겠습니다.
작성한 4개의 파일에 대한 점수가 나왔습니다.

저희가 예상했던것과 같이 처음에 생성한 singleLGBM파일에는 관객수가 음수로 표현되었습니다.
좋지 않은 모델이라 판단했고, 교차분석을 통해 생성한 kfoldLightGBM모델이 더 좋은 모델인것을 확인하였습니다.
그리고 최종적으로는 genre변수를 수치화하여 분석한 모델이 가장 좋은 점수를 얻었습니다.
의외로, 모델을 튜닝하여 얻은 분석은 더 좋지 않은 점수를 받았습니다.

랭킹을 보면 총 480개의 팀중에 121등을 한것을 확인할 수 있습니다.
결론으론, 좋은 모델, 좋은 분석, 좋은 예측을 하기위해선 먼저 양질의 데이터가 필요하다 생각합니다.
그리고 많은 데이터를 분석하기 위해 가공하고 분석하는것이 중요하다고 생각합니다.
따라서 genre컬럼을 수치화했던것 뿐만 아니라 그 외의 데이터들을 분석하여 더욱 유의미한 데이터로 가공하여 분석한다면 더 좋은 결과를 얻을수 있을것이라 생각합니다.
'Project' 카테고리의 다른 글
| [엔지니어링산업 설계대전] (0) | 2021.06.20 |
|---|---|
| [Dacon]따릉이 이용 예측 AI모델 (0) | 2021.01.27 |
| [Kaggle]타이타닉 생존자 예측 프로젝트 (1) | 2021.01.24 |
| [Kaggle]Covid in 한국 (0) | 2021.01.21 |